从零基础开始的Python编程之路(一步一步学习如何进入Python编程界面)
24
2025-01-08
在互联网时代,大量的数据分散在各种网站上,而如何高效地获取这些数据成为了许多人关注的话题。Python作为一种简单易学的编程语言,被广泛用于网络数据抓取,即爬虫技术。本文将带你从零基础开始学习Python爬虫,并通过实战项目的方式加深对爬虫技术的理解,最终达到掌握Python爬虫技能的目标。

准备工作:安装Python和相关库
在开始学习Python爬虫之前,我们首先需要安装Python和相关的库。这一部分将介绍如何下载和安装Python,以及如何使用pip命令安装必要的库,如requests、beautifulsoup等。
初识Python语言:基本语法和常用数据结构
在学习任何一门编程语言之前,我们都需要了解其基本语法和常用数据结构。本章将带你快速入门Python语言,并介绍一些常用的数据类型和数据结构,为后续的爬虫学习打下基础。

HTTP协议与网络请求:掌握网络通信基础
在进行网络数据抓取之前,我们需要了解HTTP协议和网络请求的基本知识。本章将介绍HTTP协议的基本原理,以及如何使用Python发送网络请求,获取网页内容。
网页解析:初步了解HTML和CSS
网页是我们获取数据的主要来源,而要从网页中提取我们需要的信息,就需要对网页的结构进行解析。本章将简要介绍HTML和CSS的基本知识,以及如何使用Python解析网页内容。
常用爬虫库:学习并使用常用的爬虫库
Python有许多强大的爬虫库,如Scrapy、Selenium等,这些库可以帮助我们更加便捷地进行数据抓取。本章将介绍一些常用的爬虫库,并通过实例演示它们的使用方法。
高级爬虫技巧:处理动态页面和反爬机制
现代网站越来越注重安全性和用户体验,其中就包括了一些反爬机制。为了应对这些挑战,我们需要学习一些高级爬虫技巧,如处理动态页面、使用代理IP等。本章将介绍这些高级技巧,并教你如何应对反爬机制。
数据存储与处理:将抓取到的数据存储到数据库或文件
获取数据之后,我们需要将其存储起来供后续使用。本章将介绍如何使用Python将抓取到的数据存储到数据库或文件,并介绍一些常用的数据处理技巧。
实战项目:自动化抓取天气数据
通过一个实际的项目,我们可以更好地理解和应用所学的知识。本章将带你完成一个自动抓取天气数据的实战项目,从项目的需求分析、代码编写到最终运行,全程指导。
实战项目:爬取电影排行榜信息
在这个实战项目中,我们将使用Python爬虫抓取豆瓣电影排行榜的信息,并进行简单的数据分析和可视化展示。通过这个项目,你将进一步巩固和应用所学的爬虫技术。
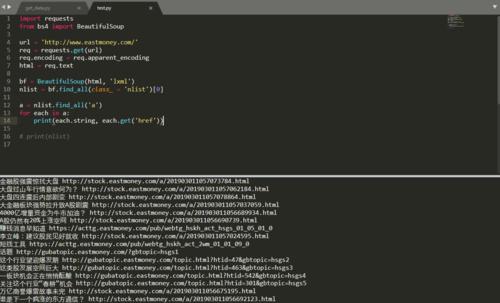
实战项目:爬取股票信息并生成报告
本章将带你完成一个实战项目,通过Python爬虫抓取股票信息,并生成股票的基本报告。这个项目将涉及到更复杂的数据处理和分析技巧,帮助你更好地应用爬虫技术。
实战项目:爬取新闻数据并进行情感分析
在这个实战项目中,我们将使用Python爬虫抓取新闻数据,并通过情感分析对新闻进行分类。这个项目将结合自然语言处理的技术,帮助你深入理解爬虫在实际场景中的应用。
实战项目:爬取网站图片并进行图像识别
本章将带你完成一个实战项目,通过Python爬虫抓取网站上的图片,并使用图像识别技术对图片进行分类。这个项目将涉及到图像处理和机器学习的知识,帮助你更好地拓展爬虫技术的应用范围。
实战项目:爬取微博数据并进行用户分析
在这个实战项目中,我们将使用Python爬虫抓取微博数据,并通过用户分析对微博用户进行画像。这个项目将结合社交网络分析的技术,帮助你更深入地了解网络数据抓取的应用场景。
常见问题解答:排除学习过程中的难点与疑惑
在学习过程中,难免会遇到一些问题和困惑。本章将回答一些常见的问题,帮助你排除学习过程中的难点,更加顺利地掌握Python爬虫技术。
与展望:从零基础到掌握爬虫技术的旅程
通过本文的学习,我们从零基础开始,逐步掌握了Python爬虫技术。通过实战项目的学习,我们不仅加深了对爬虫技术的理解,还掌握了如何将其应用于实际项目中。未来,我们可以进一步拓展爬虫技术的应用领域,并深入研究更高级的爬虫技术。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。
